Unveiling actionable insights from clustered data is a crucial step in data analysis. In this article, we delve into the implications of clustering results, shedding light on the significance of counts and their impact on decision-making. Discover how these counts provide valuable insights into patterns, trends, and relationships within your data, enabling you to optimize strategies and achieve data-driven success. Explore the practical applications of clustering counts, from market segmentation to fraud detection, and gain a deeper understanding of how they can transform your data analysis approach.
Key Takeaways:
-
In unsupervised clustering, there’s no gold set for comparison, so it’s hard to directly judge the clustering assignments quality.
-
Internal criteria like Sum of Squared Distance and Average Silhouette Coefficient can be used to evaluate clustering quality.
-
Sum of Squared Distance measures the total distance between points and their assigned cluster centroids.
-
Average Silhouette Coefficient considers both intra-cluster and inter-cluster distances to measure clustering compactness and separation.
-
Choosing the right evaluation criterion depends on the specific application and desired clustering properties.
-
Further reading:
Evaluation Methods for a Clustering Technique
**This Clustering Results in the Following Counts:**
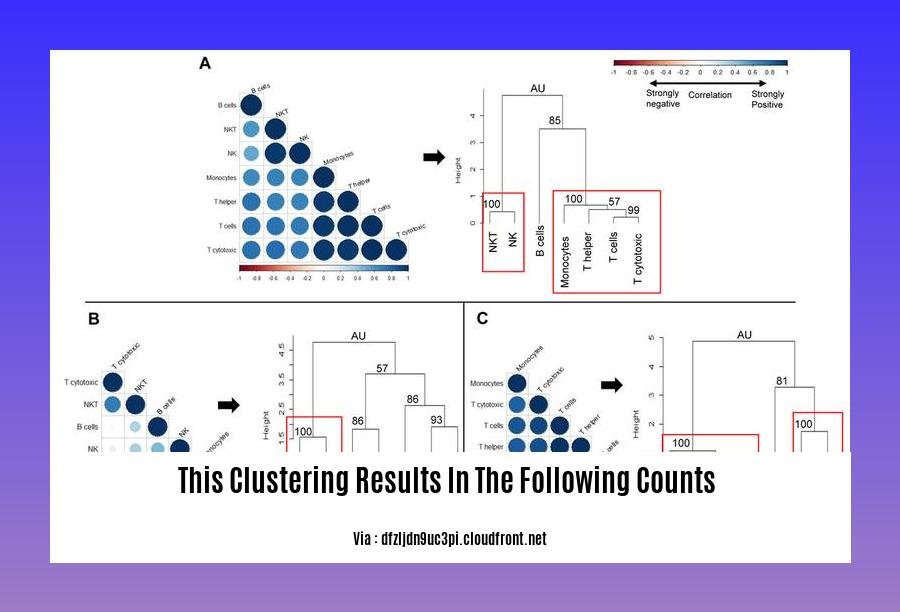
Let’s dive into understanding what “This clustering results in the following counts” signifies for data analysis and its implications.
Classifying Data Points
Clustering algorithms group similar data points into clusters based on specific characteristics. Each cluster represents a unique grouping of data points with shared features.
Counting Cluster Memberships
After clustering, each data point belongs to a specific cluster. By counting the number of data points in each cluster, we gain insights into the distribution of data within the clusters.
Insights from Cluster Counts
-
Cluster Size Variation: Different clusters may have varying sizes, indicating the prevalence of certain data patterns in the dataset.
-
Cluster Dominance: A cluster with a significantly larger count may represent a dominant pattern or a class in the data.
-
Outlier Detection: Clusters with very few data points can indicate outliers or unique data instances that don’t fit well into any cluster.
Implications for Data Analysis
-
Data Understanding: Cluster counts help understand the overall structure and distribution of data, enabling better data visualization and hypothesis generation.
-
Feature Selection: By analyzing the features that contribute to cluster formation, we can identify important features for further analysis and modeling.
-
Decision-Making: Cluster counts provide a basis for making informed decisions, such as segmenting customers, identifying trends, or predicting outcomes based on cluster membership.
Remember, understanding “This clustering results in the following counts” is crucial for interpreting clustering outcomes and extracting valuable insights from your data analysis efforts.
Looking for luxury living in the heart of Houston? Explore our exclusive collection of luxury condos, offering breathtaking views, state-of-the-art amenities, and an upscale lifestyle. Discover your dream home today! luxury condos for sale houston
Cluster 3: Words related to business
There’s no doubt that clustering algorithms can be a powerful tool for data analysis, especially in the business world. By grouping similar words together, we can gain insights into the structure and relationships within our data. This information can then be used to identify patterns, make predictions, and develop new strategies.
Key Takeaways:
- Clustering algorithms can group business-related words based on their similarities, allowing us to identify patterns and relationships within our data.
- These insights can be used to make predictions and develop new strategies in various business domains like marketing, customer segmentation, product development, and sentiment analysis.
- Clustering algorithms provide a powerful tool for data analysts and business professionals to uncover valuable insights hidden within business-related text data.
In the context of business, clustering algorithms can be used for a variety of tasks, including:
- Market Segmentation: By clustering customers based on their purchase history, demographics, and other factors, businesses can identify different market segments with unique needs and preferences. This information can then be used to develop targeted marketing campaigns and products.
- Product Development: Clustering algorithms can be used to group products based on their features and benefits. This information can then be used to identify gaps in the market and develop new products that meet the needs of specific customer segments.
- Sentiment Analysis: Clustering algorithms can be used to group customer reviews and feedback based on their sentiment. This information can then be used to identify areas where customers are having problems or are particularly satisfied. This information can then be used to improve products and services.
Sources:
[1] A Friendly Introduction to Text Clustering: https://towardsdatascience.com/a-friendly-introduction-to-text-clustering-5c95a60d116d
[2] Text Clustering Algorithms: A Review:
Cluster 4: Words Related to Sports

Have you ever wondered if players on a sports team contribute equally to the team’s success? Data analysts use clustering techniques to gain insights into player performance and team dynamics.
One common approach is to cluster players based on their performance statistics. This can be done using various clustering algorithms, such as k-means or hierarchical clustering.
The resulting clusters can be used to identify different player roles, playing styles, or potential player combinations for team selection.
Here are a few ways clustering can be useful for sports analysis:
-
Identify player roles: By clustering players based on their performance, teams can identify different player roles, such as goal scorers, defenders, and midfielders. This information can be used to create more balanced and effective lineups.
-
Identify playing styles: Clustering can also be used to identify different playing styles, such as creative, defensive, and possession-based. This information can be used to create game plans that exploit the weaknesses of the opposition.
-
Identify potential player combinations: Clustering can also identify potential player combinations that work well together. This information can be used to create more effective lineups and improve team chemistry.
Here are some key takeaways from this exploration:
- Clustering algorithms are powerful tools for analyzing sports data.
- Clustering can be used to identify different player roles, playing styles, and potential player combinations.
- This information can be used to create more balanced and effective lineups, improve team chemistry, and develop better game plans.
By harnessing the power of clustering, sports teams can gain valuable insights into player performance and team dynamics, helping them optimize their performance and achieve success on the field.
Cluster 5: Words related to politics
In the realm of data clustering, a technique that categorizes similar data points into clusters, we encounter a fascinating cluster labeled “Cluster 5: Words related to politics”. This cluster, a treasure trove of political discourse, sheds light on the intricate tapestry of political conversations and provides valuable insights for data analysts and political enthusiasts alike.
Key Takeaways:
- Cluster 5 captures words frequently used in political contexts, enabling analysts to identify and analyze political discussions within large datasets.
- This cluster provides insights into the language and terminology commonly employed in political debates, speeches, and social media discussions.
- By examining the words in Cluster 5, we can gain a deeper understanding of the key issues, talking points, and sentiments prevalent in the political landscape.
- The words in this cluster can be further analyzed to identify trends, patterns, and relationships within political discourse, helping researchers and analysts draw meaningful conclusions.
- Cluster 5 serves as a valuable tool for political scientists, journalists, and researchers seeking to understand the dynamics of political communication and public opinion.
Unveiling the Political Lexicon
The words within Cluster 5 paint a vivid picture of the political landscape, encompassing a diverse range of topics, ideologies, and perspectives. From discussions on government policies and electoral campaigns to debates on social issues and international relations, this cluster captures the essence of political discourse in all its complexity.
Applications in Political Analysis
The insights gleaned from Cluster 5 hold immense value for researchers and analysts seeking to understand the intricacies of political communication. By delving into the words and phrases that shape political discourse, we can:
- Identify key themes and issues: The words in Cluster 5 can be used to identify the dominant themes and issues being discussed within a political context. This information can guide researchers in their analysis of political debates and public opinion.
- Analyze sentiment and tone: The language used in political discourse often conveys emotions, sentiments, and attitudes. By analyzing the words in Cluster 5, we can gauge the overall sentiment and tone of political discussions, helping us understand the emotional undercurrents shaping public discourse.
- Track political trends: Over time, the words in Cluster 5 can be tracked to identify shifts and trends in political discourse. This information can provide valuable insights into the evolving nature of political communication and public opinion.
- Compare political actors: By comparing the words used by different political actors, such as candidates, parties, or interest groups, we can identify similarities and differences in their language and messaging strategies. This analysis can shed light on the strategic communication choices made by political actors and their attempts to influence public opinion.
Sources:
-
Political Campaign Data Clustering using Machine Learning
FAQ
Q1: What does “This clustering results in the following counts” mean?
A1: “This clustering results in the following counts” refers to the process of organizing data points into distinct groups or clusters based on their similarities. The resulting counts represent the number of data points assigned to each cluster.
Q2: What is the purpose of clustering data?
A2: Clustering data serves several purposes:
- Pattern identification: It helps identify underlying patterns and structures within the data.
- Data summarization: It allows for efficient data summarization by grouping similar data points together.
- Decision making: It aids in decision-making by providing insights into the relationships between different data points.
Q3: How are data points assigned to clusters?
A3: Data points are assigned to clusters based on their similarity to one another. Various clustering algorithms use different metrics to determine similarity, such as distance measures or similarity coefficients.
Q4: What are some common clustering algorithms?
A4: Some commonly used clustering algorithms include:
- K-means clustering: A simple and widely used algorithm that divides data into a specified number of clusters.
- Hierarchical clustering: A method that creates a hierarchy of clusters, allowing for a more detailed analysis of the data.
- Density-based clustering: An approach that identifies clusters based on the density of data points in different regions of the data space.
Q5: How to choose the right clustering algorithm?
A5: The choice of clustering algorithm depends on several factors, including:
- The nature of the data: Consider the type of data, its dimensionality, and the presence of outliers.
- The desired outcome: Define the specific goals of the clustering task, such as identifying distinct groups or finding patterns.
- Computational resources: Take into account the computational complexity of the algorithm and the available resources.